llms.txt: what it is, and whether your site needs one
July 4, 2026
llms.txt is one of those ideas that sounds inevitable the first time you hear it. Robots.txt tells search crawlers where they can go, so surely there should be an llms.txt that tells AI models what your site is about. The file exists, it is easy to add, and a growing number of sites have one. The honest question is whether it does anything. Here is the 2026 picture, including the parts most guides skip.
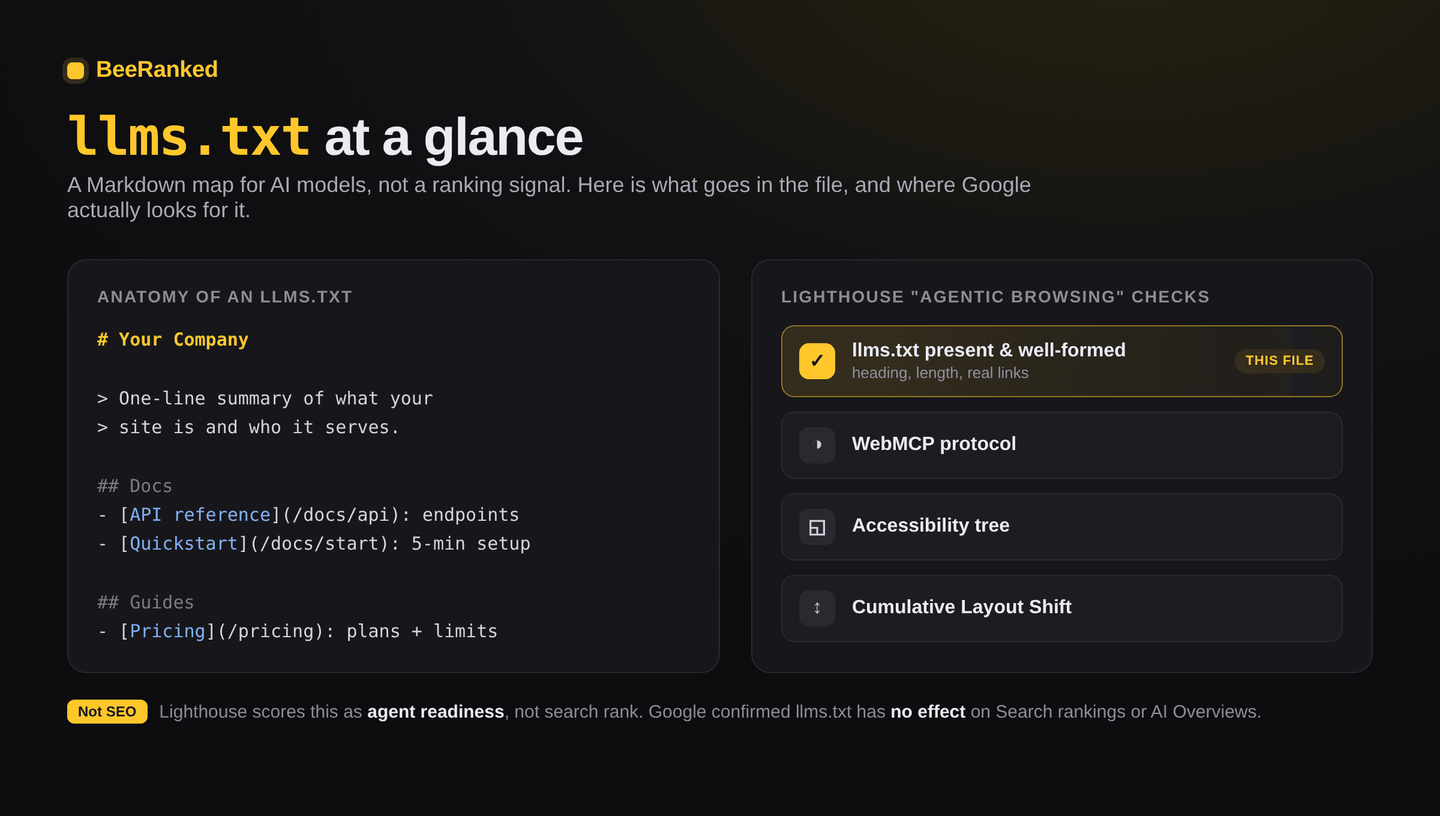
The short version: llms.txt is a proposed plain-text file that gives AI models a clean, Markdown map of your most important pages. It is a community convention, not a standard any major AI company has committed to reading, and there is no evidence yet that it improves your visibility in AI search. It does have a genuine niche, and as of May 2026 it also turns a check green in Google's Lighthouse report, though not the one you might think. For most sites it is a five-minute job with little downside and modest upside. Whether to add one comes down to what kind of site you run.
What llms.txt actually is
Proposed in 2024 by Jeremy Howard of Answer.AI, llms.txt is a single file you place at the root of your domain, at /llms.txt. Inside is Markdown, not code: a short description of your site followed by curated links to the pages you most want a model to read, each with a one-line note on what it covers. The pitch is efficiency. Instead of a model crawling your rendered HTML and wading through nav bars, cookie banners and markup, it can read a tidy summary and jump straight to the pages that matter.
It is worth being precise about what it is not. It is not robots.txt: robots.txt controls access, llms.txt suggests reading. It does not replace your XML sitemap, and it does not change how Google indexes your site. And despite the name, it is aimed at language models, not the search crawlers that have read your pages for years.
Who actually reads it
This is where the honest version diverges from the hype. As of 2026, no major AI company, not OpenAI, Google, Anthropic, Meta or Mistral, has publicly committed to reading llms.txt in their production systems. Perplexity is the name most often cited as retrieving it, and a few others appear to fetch it inconsistently. But there is no promise, from anyone large, that publishing the file changes what a model knows about you.
The usage data is sobering. One analysis of roughly 38,000 domains with a valid llms.txt found that 97% received zero requests for the file in a recent month. Adoption is climbing fast, but the files mostly sit unread, and controlled studies looking for a link between having an llms.txt and performing better in AI answers have not found one.
The twist: Google's own Lighthouse now checks for it
Here is the wrinkle that makes this genuinely confusing. In May 2026, Chrome's Lighthouse, the auditing tool built into Chrome DevTools and PageSpeed Insights, promoted a new Agentic Browsing category into its default report. One of the four things it checks is whether your site has an llms.txt. The other three are the WebMCP protocol, your accessibility tree and layout shift. If you do have the file, the audit also checks it is well-formed: a heading, enough length, actual links.
So Google Search says you do not need llms.txt, and Google's Chrome team added a check for it in the same season. Both are true, and they only look contradictory until you see the split. The Lighthouse audit measures whether your site is ready for AI agents to browse and act on it, not how you rank. It even scores as a simple pass-ratio rather than a weighted 0-to-100, precisely because the standards are still forming. Google reaffirmed on June 15, 2026 that llms.txt has no effect, positive or negative, on Search rankings or AI Overviews, because Search does not use it. The file is an agent-readiness signal, not a ranking signal.
That distinction is the whole game here. If you or your clients watch Lighthouse scores, a valid llms.txt now turns one more check green, which is a real, if modest, reason to add one. Just do not mistake a green Lighthouse check for a ranking gain. They live in different worlds.
The one place it genuinely helps
Beyond the audit, there is a real functional use case, and it is narrow: developer documentation consumed by AI coding assistants. Tools like Cursor, GitHub Copilot and Claude pull docs into their context while a developer works, and every token of nav and boilerplate they have to read is wasted budget. A clean llms.txt that points straight at your API reference and guides makes those tools faster and more accurate at citing your product. It is telling that the companies with a polished llms.txt tend to be developer platforms, Anthropic, Cloudflare and Stripe among them. If you publish docs that AI coding tools read, the file earns its keep.
For a marketing site, a blog or a storefront, that specific payoff mostly does not apply.
So should you add one?
A reasonable rule: add it if it is cheap, and hold it in the right box, agent readiness, not rankings.
If you run developer docs or an API, publish one. The dev-tooling benefit is real and the file is easy to generate. Some CMS and doc platforms now create it for you.
If you or your clients live by Lighthouse scores, a valid, well-formed llms.txt now passes one of the new agentic-browsing checks. That is a legitimate reason to add one, as long as you read it as a green audit, not a ranking lift.
If you run a normal content site and ignore Lighthouse, you can still add a basic llms.txt for the small chance the ecosystem matures, but treat it as insurance, not strategy.
Either way, keep it honest and maintained. A stale llms.txt pointing at pages that have moved is worse than none at all.
The trap is spending a week perfecting a file that, for now, mostly moves an audit score, while the things that actually determine whether AI tools cite you go untouched.
What actually gets you cited in AI search
If a text file at your domain root is not the ranking lever, what is? The same fundamentals that were pulling ahead before llms.txt existed:
Authority and mentions. Answer engines cite sources they can corroborate across the web. Being referenced by other credible sites does far more than any file you control.
Structured content and a clear identity. Machine-legible pages, with valid structured data that spells out who you are, are what let a model attribute an answer to you by name. This is the real version of what llms.txt gestures at, and it works today. See how Google and AI search understand your brand.
Answer-first writing. Pages that state a clear answer in a passage a model can lift are the ones that get quoted. That is the whole discipline of answer engine optimization.
The right schema, emitted correctly. Not the retired rich-result types, but the entity and article markup models actually read. We covered which schema still earns its place.
Do those and you are legible to AI tools whether or not they ever fetch your llms.txt. That is the difference between a signal you hope gets read and signals that are read right now.
Where BeeRanked stands
We do not think a file at your root is where AI visibility is won, so BeeRanked does not sell you on one. What every page you publish does ship is the part that works: valid structured data, a consistent brand identity, answer-first structure and absolute, machine-readable URLs, served from your own domain so the authority compounds. See how we approach SEO. And because an llms.txt is a modest, real signal now that Lighthouse looks for it, generating one from the content you have already structured is a small step, not a rewrite.
llms.txt is a good idea the ecosystem is still catching up to. Add it where it helps, read the Lighthouse check for what it is, skip the hype, and spend the saved week making your pages the ones a machine wants to quote.
Frequently asked questions
Does llms.txt help my SEO?
Not in the traditional sense. Google confirmed on June 15, 2026 that llms.txt has no effect on Search rankings or AI Overviews, and no Google ranking system reads it. It is aimed at language models and AI agents, not search crawlers, and controlled studies have not found a link between having the file and better AI-search performance.
If Lighthouse checks for llms.txt, does that mean it is a ranking factor?
No, and this is the common mix-up. The llms.txt check lives in Lighthouse's Agentic Browsing category, which measures whether AI agents can browse and act on your site, not how you rank. A passing Lighthouse check and a ranking boost are different things that happen to both come from Google.
Is llms.txt an official standard?
No. It is a community proposal from 2024, not a specification any major AI company has committed to. Some tools retrieve it, notably in developer-tooling contexts, but there is no industry commitment to act on it.
Who should bother with one?
Sites with developer documentation that AI coding assistants read benefit most. Teams that track Lighthouse scores get a second reason, since a valid file passes the new agentic-browsing check. For a typical marketing site that ignores both, it is low-cost insurance at best, not a priority.